开发模型
这个是什么鬼东西?很多时候,我们写代码都是凭感觉去写的,所以啊,有时候写的得心应手,有时候写的莫名其妙,因为,不知道流程和先后顺序,也不知道流程的重要性,还有软件设计和预备等操作,这些一般都是总工和负责人、经理去考虑的。但是我们不是那种只会敲代码的傻瓜啊,我们得思考,得设计,得理解,不是他给我们做什么,就去做什么。这样是牛马和奴隶。
好久没更新了,开更,也算是考完试了,终于有时间更新博客了,软考考砸了捏,呜呜呜。
这个什么是意思呢?就是字面意思,首先,我们当前的git仓库是一个主模块,但是,我不可能一个主模块可以实现所有功能的啊,这个时候就像项目需要调用其他模块和代码一样。主模块有时候也需要子模块,然后调用子模块才能正常工作。
1 | git submodule init |
下载子模块很简单,切换子模块就是进入子模块目录就ok了。注意了,如果修改了子模块想要推送的话。就得进入子模块中,才能进行提交和推送,此时,你得有管理员权限或者提交权限才可以哦,不然是无法更新子模块的,你在主模块中的提交是不包括子模块的。
首先呢,.git文件是不允许随意修改的,这个在提交的时候很多东西不会提交,只会上传那些操作和提交记录等,本地就有很多脚本和hook。但是还有一个gitmodule的文件,这里包含了子模块的名称和url。因为主模块不知道子模块要些什么东西,所以给了比较大的权限。所以,如果下载到有病毒的子模块,那么就可以在下载子模块去修改主模块的钩子和脚本,等某个操作执行完毕就触发hook,去执行恶意代码。
不过现在好像修复了,不过有些版本还是会有这个问题的。
现在登录github界面就可以看到要二级密码登录了。也就是2FA了,我感觉国内的gitee可能也要上这个,因为喜欢抄嘛。现在,我感觉是在观望github的二级密码怎么样。
[Git] 一次搞定:Github 2FA(Two-Factor Authentication/两因素认证) - 千千寰宇 - 博客园 (cnblogs.com)
可以根据如上操作,进行绑定,至于软件,随便找一个2FA的软件就ok了。
这个就很简答了,在仓库设置中添加删除保护就好了。
这个问题,我也是第一次遇到,就是我在公司进入gitee的企业版嘛,我fork了一个项目,我却发现不能删除了,这个让我非常吃惊!我删除这个fork的库,竟然也要管理员同意,看来是对库进行额外的保护。
git确实厉害,已经离不开了,我想起来之前那个linux开源社区的大问题,有一个黑客Jia Tan,通过一个解压软件就实现了,入侵,它修改了脚本,让脚本在运行的时候,故意中断,这样就可以进入其他地方去工作了,因为脚本不想代码可以编译找出bug的,所以非常难以发现。所以,这些个开源软件,我只能说一定每一个后面都有后门,希望,这些bug早日修复,希望有更多人注意开源安全和网络安全。
PCI-E总线是一种通用的总线规格,它由Intel所提倡和推广,其最终的设计目的是为了取代现有 电脑系统 内部的总线 传输接口 ,这不只包括 显示接口 ,还囊括了 CPU 、PCI、HDD、Network等多种应用接口。

首先就是差分信号,其次就是全双工,有点422的味道了,还有就是支持热插拔,对了pci也是支持热插拔的,高速,多个设备等。
即允许在同一时刻,同时进行发送和接收数据。如下图所示,设备A和设备B之间通过双向的Link相连接,每个Link支持1到32个通道(Lane)PCIe使用的是8b/10b的编码。
为了实现直流均衡。在高速串行通信中,8B/10B编码是一种经常用到的编码方式。而高速串行总线中,通常采用交流耦合方式,即在发送端(TX)串接电容,根据电容“隔直流,通交流”的特性,或者理想电容的阻抗公式:
电容阻抗公式
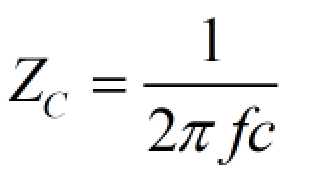
信号频率越高,电容阻抗越低。当数据位流中出现多个连续的1或0时,可以认为该时间段信号是直流的,电容的损耗变大,导致信号的幅度降低,直流信号被滤除,到最后无法识别是1还是0。而且接收端收到连续的1或0时,没有充分的定时信息,对接收端的解码带来了困难。其原理如下图所示:
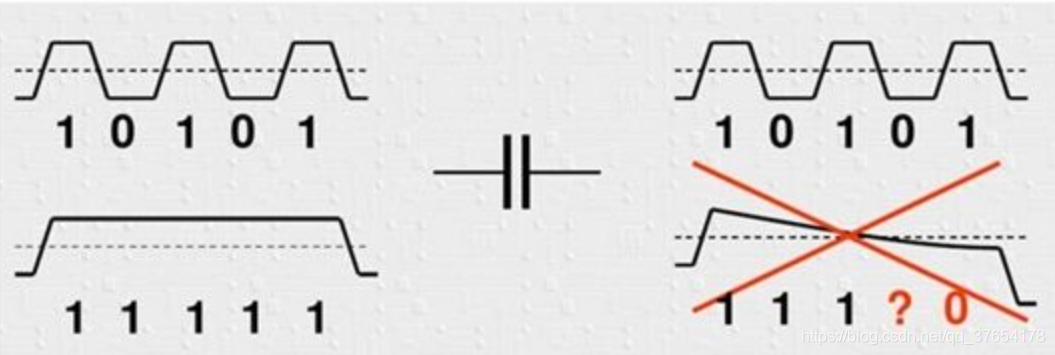
8B/10B编码以字节为单位,将数据映射成10位宽度的数据(具体映射方式可查表),使得编码后的二进制数据流中1和0的数量基本保持一致,同时确保字节同步易于实现。
PCIe协议是一种端对端的互连协议,一个典型的PCIe系统框图如下:
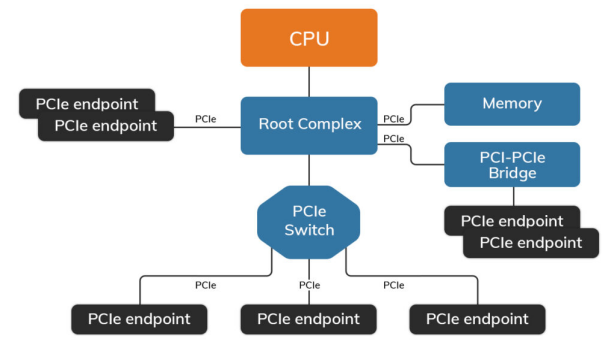
与PCIe拓扑结构相关的其他术语如下:
Root Complex我们简称为根复合体。根复合体将CPU和内存子系统(Memory)连接到由一个或多个PCIe或PCI设备组成的PCI Express交换结构。它是PCI反向树拓扑结构的“根”,代表CPU与其他设备进行通信。
PCIe endpoint就是PCIe的终端设备/PCIe终结点。PCIe终端设备可以直接与根设备进行连接,也可以通过Swith交换设备与根设备连接(交换设备类似于接口扩展功能)。
根据PCIe规范,在PCIe拓扑中可以有256个总线,每个总线上有32个设备,每个设备有8个功能。一个终节点最多可以支持8个功能,每个功能都有自己独立的配置空间。
例如:基于PCIe的非易失性内存(NVM)和基于PCIe的固态硬盘(SSD)是计算机系统中的两种终节点设备。
PCIe桥接器:桥接器可以将PCI设备的请求转换为PCIe x1规范的请求,并连接到计算机PCIe插槽上。工作流程如下:
主设备发送带有必要参数的请求到PCIe桥接器。
PCIe桥接器接收请求并进行协议转换,将PCI请求转换为适合PCIe接口的形式。
转换后的请求在PCIe接口上发起点对点传输。
请求在接口通道上进行传输,通过PCIe总线连接到目标设备。
通过这种方式,PCI设备能够利用PCIe插槽和接口连接到计算机系统,实现数据和控制的交换。
PCIe体系结构包括应用层、事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。
PCIe-x只是一个接口协议,如果大家都老老实实就好了,但是,这个接口而已嘛,想要干嘛就可以干嘛,只要两边对上引脚和协议就ok了。
PCIE1.0/PCIE2.0/PCIE3.0/PCIE4.0/PCIE5.0
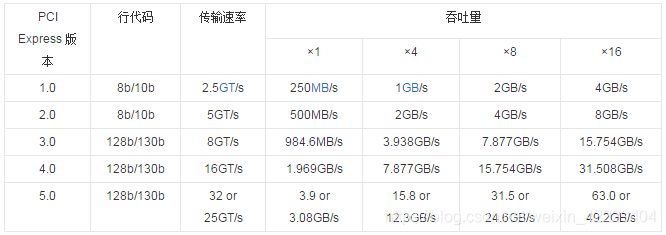
PCIe的向下兼容性体现在以下几个方面:PCIe具有向下兼容的特性,这意味着较新版本的PCIe插槽和设备可以与较旧版本的PCIe插槽和设备进行互操作。这种兼容性确保了新设备可以与旧设备一起使用,从而减少了升级和更换设备时的不便。
插槽兼容性:较新版本的PCIe插槽通常可以容纳较旧版本的PCIe卡。例如,一个PCIe x16插槽通常可以容纳任何较小的PCIe卡,如PCIe x8、PCIe x4或PCIe x1。这意味着您可以将较旧的PCIe卡插入较新的插槽中,以实现互操作性。
带宽适配:如果您将一个使用较少通道的PCIe卡插入一个具有更多通道的PCIe插槽中,系统会自动适配带宽。例如,将一个PCIe x1卡插入PCIe x16插槽中,系统会将该卡的带宽限制为PCIe x1的速度。这确保了卡与插槽之间的通信不会出现不匹配问题。
协议兼容性:即使新版本的PCIe协议引入了一些新功能和特性,但它们通常会保持与旧版本的兼容性。这意味着使用旧版本PCIe设备的系统不会因为新版本PCIe插槽而出现兼容性问题。
供电兼容性:PCIe插槽还需要向下兼容供电。较新的PCIe插槽可以为较旧版本的PCIe卡提供适当的电源。这确保了即使插槽能够提供更高的电源能力,也不会损坏较旧的卡。
PCIe的向下兼容性使得用户能够在升级或更换设备时更加灵活,无需担心新设备是否与旧设备兼容。这种特性有助于维持系统的稳定性和灵活性,同时节省了升级成本。
显卡、固态硬盘(PCIe接口形式)、无线网卡、有线网卡、声卡、视频采集卡、PCIe转接M.2接口、PCIe转接USB接口、PCIe转接Tpye-C接口
因为,我们看到PCIe是有物理层的,所以,我们其实就可以单独使用物理层一个就可以了,什么意思就是,插口卡口是固定的,但是接的线是可以改动的,我不一定要按照它的协议进行设计,我也可以用我自己的接口引脚协议,只要两个设备统一引脚和接线协议就好了。
PCIe是一个高级的协议和接口,它在iso层级中有4层使用方法,所以,它不但是硬件协议,还是软件协议,自然是只有高端的嵌入式设备或者高性能设备才有使用到的资格,但是,只是使用硬件协议,就是那些接口的话,啥地方都能用的。