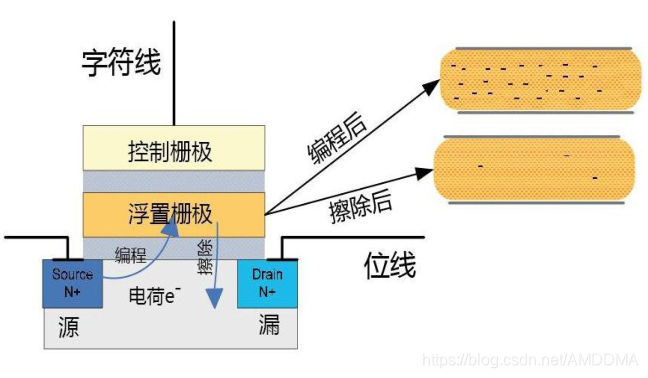
电源问题
这个问题,非常容易忽略,也就是,目标设备是否有外部电源或者内部电源。这个问题会影响到生产中的一些措施,设置连开发过程都会影响。
一直使用swdio进行debug,却没注意到,这个swdio的vcc已经承担了供电的职责,可能会忽略没有供电的时候出现的异常bug。其实,内部线路,可能是有问题的,但是供电有了反而一切都是正常的,很可能硬件握手失败都开不了机呢。常见于热插拔设备上面。
外部电源,这个电源是多大的,这个电源太大了怎么办,工人进行装配的会不会出现需要外部供电才能进行处理的操作,如何升级,如何操作等。
内部电源,这个常见就是低功耗问题了,要知道一个设备的寿命,可以用多久,一般都是按照几年来处理的,一些物联网设备,或者可以外接电源的时候随便充电的策略。
发热问题,这个其实很多时候也是会影响设备运行的,cpu和gpu那些都是要散热的,同理,你的温度可能会到值金属变形,可能导致电机行程异常,主控宕机,硬件损毁等诸多问题
生产顺序
这个问题,还是在电子件、模块、结构之间的顺序问题。
- 后配置电子件,然后通过外部来进行标定和升级,这个常见于传感器和adc上面,因为只有结构装备完毕才能保证数据是正确无误的。
- 先配置电子件,就是比如序列号啥的的,一些协议,数据,功能啥的,都不需要外部结构,而是可以通过模块来实现操作的,这个就不用担心外部的结构了,所以可以先配置好电子件,然后在安装。
- 模块和结构,这个可以认为模块和结构合二为一,又或者说只有结构,模块就是普通的引脚电平啥的,这个时候就看是否是传感器类型的了,只是电平开关的话,就非常好处理了。
标准治具
也是一个生产规格的问题了,电机、adc、大小、孔径等,这些一系列的东西都是需要一个标准来检测和处理,这个时候就需要治具了
电机治具,这个就是检测在行程之内的速度、电流、行程等处理,也可以在电机上面添加霍尔传感器来知道此时电机位置等方法,来确保电机是正常的,这样就组装了
孔径治具,可以直接发射光束来作为标准,上面发送,下面接收,就知道误差范围了,这个治具设计就非常复杂和严谨,还得注意考虑灯丝温度和治具措施,一般都是购买国外进口的专门测试工具
通信治具,写好一个设备,肯定需要快速检测,一般用于测试从机,因为工人是不懂代码的,只想快速验证。所以,一个比较简单,比较快速验证产品正常的东西是利于生产和检测的。
老化治具,就是专门用来跑的,超频,提速,升温,升压,低温等处理,这个就是为了检测寿命的,一般是老化柜那样的东西,不过,想要自己做一个快速测试,也不难的。
长度治具,这个就是尺子了,没啥好说的了。最多是来规定一些电机的运行行程,来保证统一。
还有很多奇奇怪怪的治具。
测试日志
测试的时候,最好有记录和日志,这样方便bug复现和审查。
所以,串口数据,如果可以还是保留一下,linux的话,就是echo打印出来,重定向输出到专门的日志文件。这个就是看个人习惯了。运维的肯定就非常熟悉了,这个肯定是必不可失的部分,如果连复现都无法做到,这个bug也是根本不可能修复的。
电气规则
常见的ttl 232 485 can等那些电气特性,还有usb pcie m.2 等特有热插拔电气特性。
产品生产环境
这个,实验室环境、无尘、温度、压强、电源等问题,都可能会导致传感器的误差,这些都是可以避免的,不过很多时候应该影响不大的,注意强磁强电、大噪声等环境问题、灰尘如果进入电路板很可能导致一些未知bug,最好也是杜绝为好。
设备寿命和老化
这个上面有一个老化治具的设计思路,其本质还是担心设备的耐久度,这个就非常值得考虑了,不能说,一个产品用两天就坏了,那谁还买啊,差评如潮。
但是,设备不是永久的,是一定有寿命的,一般是越是大型设备,寿命越长,越是消费电子,寿命越短,物联网设备,一般是几年左右,所以,这里就有内外电池的考虑,太阳能的考虑等
工作环境差异
设备工作区域,多热,外壳会不会化了,内部会不会积热,会不会进水,会不会受到干扰导致起振失败,导致内部emp,共振、振动环境导致螺丝和接口等松动、温度差异带来的传感器误差,电池寿命,电池电量这些都是非常大的问题,都是需要考虑进去的
焊接和贴片机
这个常常发生在pcb生产中,因为国产贴片机的问题太多了,抛料都是正常的现象,后续硬件工程师虚焊也是正常的东西,所以,就非常有必要治具了,确保电子件安装到产品设备之前是正常的。
安全和高效检测设计
这个就是比如,安装空调外机,安装复杂大型设备,不方便拆卸等情况,就需要留一个专门的接口给外部,外部调试线连接测试,就可以立刻知道设备当前状态如何,是否可以确保正常运行,这个高效,同时也一定程度上增加了安全性。这样可以高效抽查,极大程度缩短检测时间,提高现场检测的能力。
自然安全性这个就是要单独拿出来分析的,产品外壳毒性,电路板毒性,任天堂以前的卡带上面就有一些化学物质,非常非常苦,就是为了防止人去舔以及误食,这个也是一个出于安全的设计。外部结构设计是否安全,电路内部电容,电路线,电源线,dc-dc模块等问题。不能像机革那样,自己电脑炸了,还怪用户,至少得保证自己产品不得爆炸吧,三星爆炸手机可是深得人心。
运输结构设计
不能说一个设备长的和刀子一样吧,也就是说,运输的时候,要么就是有配套的外壳和箱子,要么就是设计成方便运行的结构,这个都是机械佬考虑的了,主要还是以应用场景和大小为主。
产品差异补偿
没人敢打包票说每个设备都是ok的,都是一模一样的,一定有残次品,这就是良品率了。优化生产过程,减少外界干扰,多用治具来保证产品的正常,增减检测工序,这个注定是没有最好,只有最适合了。
华为甚至更加过分,屏幕抽奖,一个手机的屏幕,几家厂商提供的产品,每个手机都想抽奖一样,这就导致了产品差异是非常大,如何软件进行调教,硬件去弥补,去做误差补偿,如色域、光亮、帧率等。这个问题是永远没有最佳方案的,都是就事论事,根据实际情况去分析和处理。
生产安全
这个是重中之重,想都不要想,只要出了一条人命和残疾,那不得了,不只是赔钱的问题,而是生产线都可能出现大问题,带来连锁反应,带来的负面影响都是不可估量的。
用电安全,设备摆放,工具摆放,特殊化学品处理区和存储区,禁止明火,不要堵路,地面防滑,尖锐突出,禁止打闹追逐,防夹,注意生产车间的机床注意实现,注意远离机床,不要为了效率而增加风险,一切高危都要做安全措施,不要靠近大型设备等诸多安全问题。
代码设计和能力需求
作为公司项目,肯定不是做着玩的,也肯定不会只有一个,所以,不同的设备就有不同的序列号和参数属性了。同时就要求有可以使用、可以修改的接口。至于使用c cpp rust python 还是什么,只要能实现功能就是好语言,qt可以用python和cpp啊,EPS32和mcu开发也可以实现cpp和python,linux的话,建议还是c开发,也可以使用rust,还可以使用luna,有需求就可以去学习。语言知识一个工具,只要能实现功能就好了。
产品代码加密
要想办法做密钥之类的,东西,加密自己的程序,比如使用section这些来对重要函数进行加密,然后再写回flash,这个是一个很好的加密手段。
上位机
一般产品尤其是控制,遥控,定位的设备,一般都是出异常后需要用户自行矫正的,这个时候,上位机就很有存在的必要,它往往需要跨平台,需要满足多设备,多屏幕。本质就是数据收发而已,不同产品需要校准和设计的上位机是不同的。其实有的时候,会考虑,为什么不用上位机,为什么用上位机呢?我感觉是要分场景的,比如我这里是生产工厂,生产工厂需要电脑吗?自然是除了烧录代码可能需要,测试,也是装机之后才能测试,所以,不存在一边烧录一边测试的太少了。
如果我们是直接面向工厂的,此时,开发一个上位机要考虑的东西,有很多的,电脑本身其实是一个不稳定,环境差异大,不实用的生产平台。而且员工很多都不会用电脑,电脑也容易误触。所以,一个生产治具是最好的了,可以先把代码烧录到治具中,在治具中进行烧录其他设备的操作,这样员工只要操作治具就好了,一个治具是比电脑稳定很多的,而且也不存在环境差异问题。
做过linux开发就知道了,linux难就难在环境配置,系统配置上,真的天差地别,时不时就是我这里运行正常,你那边就跑不了的bug,非常痛苦,如果我直接寄一个硬件治具过来,作为烧录、测试、标定的设备,那么一下子我们就成功同步了,对于直面工厂,生产来说,这个确实是比上位机可靠好用的。上位机更适合代码烧录,固件更新,用户自定义和调节,不适合生产,也不利于生产,治具效率高,体积小,速度快,上位机一般都是一对一,这就比不上治具可以一下子插上去一堆。
上位机的优势:适合客户自定义操作,更新,微调,这个算是售后,一般都是一对一进行操作,也可以用于给用户进行检修等操作。
治具的优势:对接工厂,同步环境和标准,增加生产效率,降低员工要求,设备可靠,可以实现一对多的高效生产需求和测试需求。
统一标准
这个怎么理解呢?不单单是产品的规格,还有就是产品的标准尺度,就像卷尺一样,施工场地的单位长度都不一样呢。
统一标准,就是啥都是一样的,所以,很简单,只要所有车间和工厂都是用一样的标准,就可以做到规范和误差容许。
还有一种就是目标是标准,但是初始配置是不一样的。比如,电机此时速度是100,另一个是200,一样的最大加速度,但是我都要跑2000米,使用pid进行调制之后,就要定位,这个就是需要一个标准。而且两个因为初始速度不一样,所以最后pid调制停下来的位置是不一样的,不过误差可以接受就行了,此时就可以进行一个数据定位,只要电机复位+运行时间,就可以运行到2000米,但是如果你把100的电机速度得到的运行时间给到了200的电机速度的电机时间,就会导致,误差增加,此时,就是违反了统一标准的规则,他们应该都是对其统一标准才对。