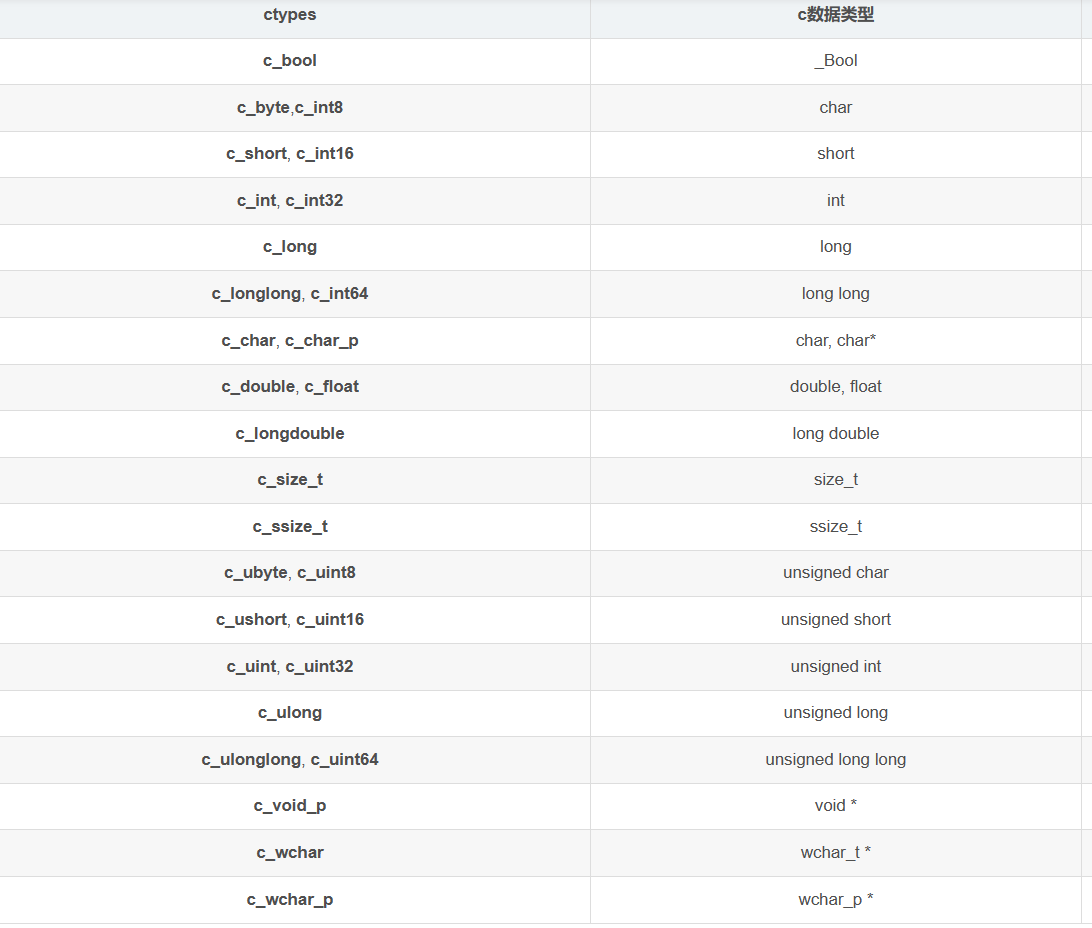
CPU多级缓存
为什么需要多级缓存的存在呢?因为,内存太大了,不论是固态还是机械去读取都太慢了,但是cpu的频率又高的吓人,还有多级流水和,流水线设计方案等(比如结构冒险,数据冒险,时间冒险等方案,所以处理起来相当迅速)。所以,总不能让cpu在原地急得跺脚吧,这纯纯浪费资源呢,所以,就想到缓存操作。
cache高速缓存
这个,就是直接与cpu连接的一个缓存了,也可以说是速度最快的缓存了,他会提前把需要的数据从内存中提取出来,等待cpu调度和使用,这个非常好用,非常nice了,这就让cpu有的忙了,但是,问题因此来了,为什么cache快呢?就是因为它小啊,而且距离近。cpu处理任务是需要得到所有数据的,cache不可能存放所有数据的,这就来了一个cache命中率问题了。cache命中率越高,就说明了,cpu可以直接cache中得到数据,这是最好最快的。超出cache的就得去内存中找了。
一级缓存
上面的cache没捕获到,就到一级缓存中去找,这个就是离cpu第二远的了,因此内存也更大,执行的事情同上面差不多的。
比如 AMD一级数据缓存设计 AMD采用的一级缓存设计属于传统的“实数据读写缓存”设计。基于该架构的一级数据缓存主要用于存储CPU最先读取的数据;而更多的读取数据则分别存储在二级缓存和系统内存当中。
比如Intel 也有的一级缓存不存储数据,而是存储这些数据在二级缓存中的指令代码,这样就可以间接去找到来自二级缓存的数据,而且可以增加一级缓存的容量。
所以,不同的策略和设计方案,对于cpu来说,效果的好坏其实也是看实际情况的,不论是直接找数据,还是间接找指令跳转到数据,都是一种权衡之后的方案和策略,都是可行而且可靠的至于效果,只能实际测试才知道了。
二级缓存
二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。
三级缓存
同样道理,三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
主存(硬盘)
到了这一步,说明上面都没成功的捕捉到cpu所需要的数据,只能从内存中读取了,这就效率非常低下了,这个是尽量要减少,但是避免不了的,当然这东西,我肯定设计不来,我也只会纸上谈兵。
局限性
这个就有必要说一说,为什么要谈这个呢?因为,我们写代码的时候,就知道,其实,我们的数据是一般都是在一块地方的,比如一个数组,比如一堆全局变量啥的,我们看他们的地址,其实都是连起来的,所以,执行一个应用和任务的时候,就可以猜出来这附近的地址可能都是需要的数据或者代码,所以,就有局限性,这也是符合编程和存储的。就像我们学习和使用mcu的时候,避免不了就是while死循环了,这极大可能就是反复用到同一个数据,所以,一个数据被使用,是不是就意味着它接着可以继续被使用呢?
1.时间局限性:如果某数据被访问过,在未来的一段时间内,我们可能还会使用到这个数据,所以缓存就提前把这个数据加载进来并留着,这样就可以让cpu调用的时候,快速去读取。
2.空间局限性:这个就是上面说,只要读取了一块地址,是不是就说明附近的地址都可能是应用和任务所需要的数据和内容呢?所以,宁可错杀一万,不可放过一人。
这些都是缓存读取的方案,自然还有更好的,都是看厂商的想法和设计了。
内存映射
这个就是把内存直接映射到缓存之中的方法,一般是直接映射到cache中的。
1.全相联映射:所有行均可用于存放主存任何一块数据
缺点:查找最慢,当cache块装满的时候,可能需要遍历所有的cache行
正常情况下我们并不限定位置,大家随便坐,先到先得。老师如果想检查一个同学的作业的话,也可以一个一个来找,即线性搜索,当然此举必然花费老师很多时间。另外一点需要强调,学生并不是老老实实坐在座位上的,不断会有学生进来或离开,也会有同学出去后又进来但前后的坐位并不相同的情况,这样的话“线性搜索”将不再可能。
2.直接映射:每个主存块只能放到某个固定的cache行,每个主存块所属的cahe行是 主存块号 % cache总行数
假设上面例子中的教室只有20个座位,编号为0-19,全校共有400名学生,学号分别为0-399。直接映射方式的求是座位不能随便选择,而是通过学号和所有座位数的余数决定,即学号为0、20、40、60…的同学只能坐在0号座位上,同样学号为1、21、41、61…的同学只能争1号座位,后来的同学会将正坐在位置上的同学挤出去,如果1号和21号同学都要来教室的话就会发生两人不断被挤出去的情况,这就是Cache的颠簸效应(Cache Thrashing)。
3.组组相联映射:首先要对所有的cache行进行分组,每个主存块只能放到固定的cache组,每个主存块所属的cahe组是 主存块号 % cache总组数,这个就是上面的组合拳头。
为了解决直接映射的颠簸效应,遂引入了组相联映射。假设学校共有5个系,每个系均有80名学生,那我们可以这样安排座位,一系的学生只能选择0/5/10/15这4个座,二系则是1/6/11/16,依次类推,如下图所示:每个系有4个座位,这4个座位是没有顺序的,即本系的学生随意坐,但全系的80名学生将争抢这4个座位,这种分为5组的映射方式就是4路组相连映射,4路的意思是每组中有4个座位,即4个CacheLine。
总结
存储内存,一般有段式,页式,段页式存储方法,同理缓存也有多个方案,没有绝对的方案,都是合适是最好的,一般都会使用折中方案比如段页式。虽然,我们百分之99的概率遇不上这些工作和研发,但是充分理解底层,选择合适的内存管理和分配是我们可以控制,理解cpu的调度方案和原理,其实,选择一个好的文件管理系统和内存分配方案,确实可以一定程度的提高速度,自然都是理论上,一切都是以实际为主,代码和人可以跑一个就非常鸟不起啊!