DMA
直接存储器访问,看这个名字就知道了,只要知道请求访问地址,访问地址,访问大小,访问模式,就可以实现地址之间的数据转移了。常见的SPI、IIC、USART等。配置好DMA、设置好地址、大小、模式,让CPU给DMA芯片发送这个命令,就会让DMA去干活了,中间cpu都不用管DMA,这就解放了CPU,去干那些耗时而且简单的访问操作。
DMA回调
DMA有错误回调,传输一半回调,传输完毕回调,所以我们只需要在回调函数中进行处理就好了,触发中断获得cpu使用权,开干。注意要使用判断DMA是否HAL_OK的状态判断函数之后,才能使用收发哦。
而且还有一点就是DMA不同那些外设一样,它本身是触发不了什么接收和发送的,SPI绑定DMA。比如SPI接收,是因为先触发了SPI的中断,因为CPU把DMA连接到一个存储器地址和SPI上了,所以才会触发SPI_DMA的接收完毕中断回调哦
DMA通道和DMA数据流
STM32F1系列(如STM32F103)
在STM32F1系列中,DMA有通道(Channel)的概念。每个DMA控制器有多个通道,每个通道可以配置为处理一个特定的外设数据流。每个通道有它自己的寄存器集合,用于配置源地址、目的地址、数据长度等。
STM32F4系列(如STM32F407)
在STM32F4系列中,DMA有数据流(Stream)的概念。每个DMA控制器有多个数据流,每个数据流可以配置为处理一个特定的外设数据流。每个数据流有它自己的寄存器集合,用于配置源地址、目的地址、数据长度等。此外,STM32F4系列的DMA控制器还有FIFO(先入先出)机制,用于优化数据传输。
使用cube的时候,就会发现要么没有通道要么没有数据流,两者只有一个。因为他们使用也非常相似。
用F04举例子:
数据流
每个DMA控制器有8个数据流,每个数据流都能够提供源和目标之间的单向传输链路。
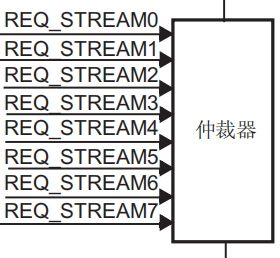
每个DMA控制器可以同时配置多个数据流,但在某一时刻只允许有一个数据流使用DMA控制器。当多个数据流同时请求时,由仲裁器决定哪一个数据流优先使用DMA控制器。
通道
每个数据流有8个通道,每个通道映射到不同外设,这有利于针对不同的产品配置不同的DMA外设请求。每个数据流只能配置为映射到一个通道,无法配置为映射到多个通道。即,与数据流不同,每个DMA控制器可以同时配置多个数据流(因为有仲裁器),但每个数据流不能同时配置多个通道(因为只有选择器)。
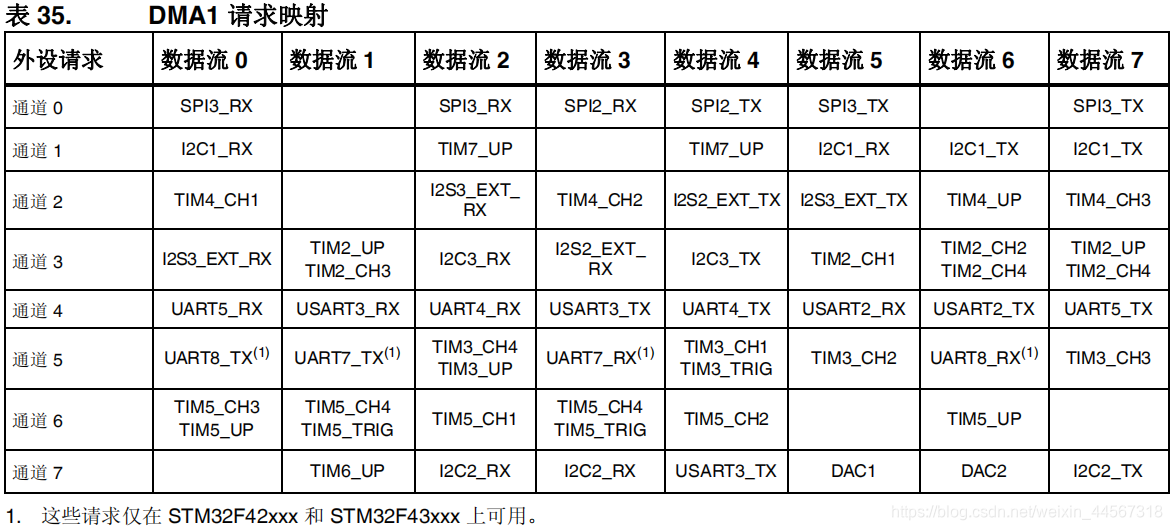
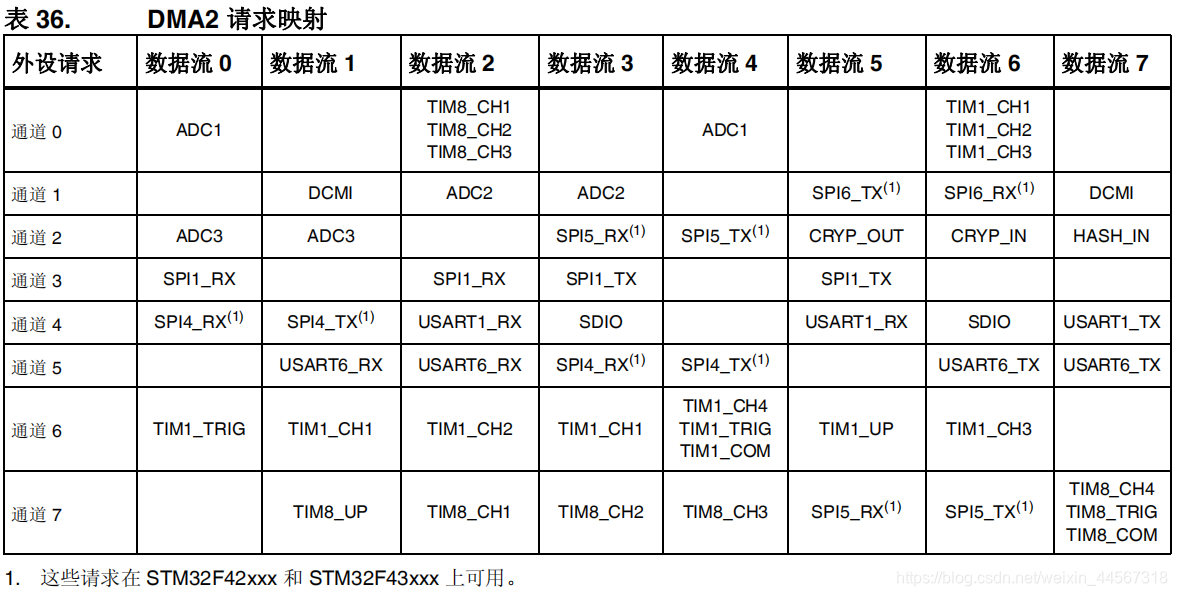
仲裁器
仲裁器用于在多个数据流同时请求时,解决请求冲突的问题。在硬件上,数据流的编号越低,请求优先级越高,仲裁器优先响应编号低的数据流。
为实现更灵活的配置,数据流还可以设置软件优先级,软件优先级分为以下4个级别:
— 非常高优先级
— 高优先级
— 中优先级
— 低优先级
硬件:如果两个请求具有相同的软件优先级,则编号低的数据流优先于编号高的数据流
原文链接:https://blog.csdn.net/weixin_44567318/article/details/114003967
总结
其实用cube配置之后,用起来差不多的,我估计这个时候也没有使用标准库了吧,后面那些H系列的,比如H745还是异构双核的。反正大家也都是对着demo进行模仿的,只要代码能用是不是标准库都是一样用的。