起因
今天在写软考题目的时候,我无意间才发现,我居然一直在按位进行寻址,但是实际上都是按照字节取地址的。cpu内通用寄存器的长度取决于机器字长。一下子,我就懵了啊?为什么不是按位取地址?为什么是按照字节?
历史原因
早期的计算机科学太夸张了,早期的计算器五花八门,大家都有各自的方法和规格,当时大家都用字进行寻址,我们知道字不是字节,字的长短是受到系统位数的影响,比如32位的字就是4字节,就是比如IBM 370就是4字节寻址,其他也有一些2字节寻址,1字节寻址等,此时内部的指令也会因为这些寻址而变得非常混乱。我个人觉得可能是因为优化了和统一指令,所以,大家一起选择使用了字节。这就是不断探索中总结出来的实践经验吧。
物理结构
其实,我们可以思考一下,如果寻址,总是寻找一个地方的高低电平,这其实是对开发来说,是毁灭的打击,这就像寄存器编程一样非常痛苦,如果是按照字节寻址就可以得到一个字符,这个意义就很大了,可以组成一段话,可以组成有用的数据。所以,就设计成了一个字线上面有8个位的物理结构设计,此时,也可以做到对位操作,也可以寻址,一举两得。
下面就是一个最基础的位的存储单元
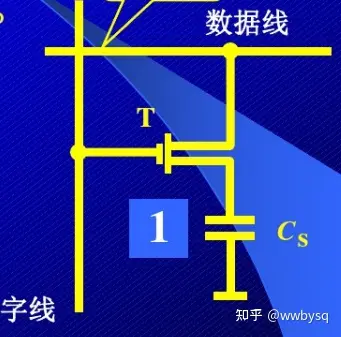
下面是一个字线的物理结构
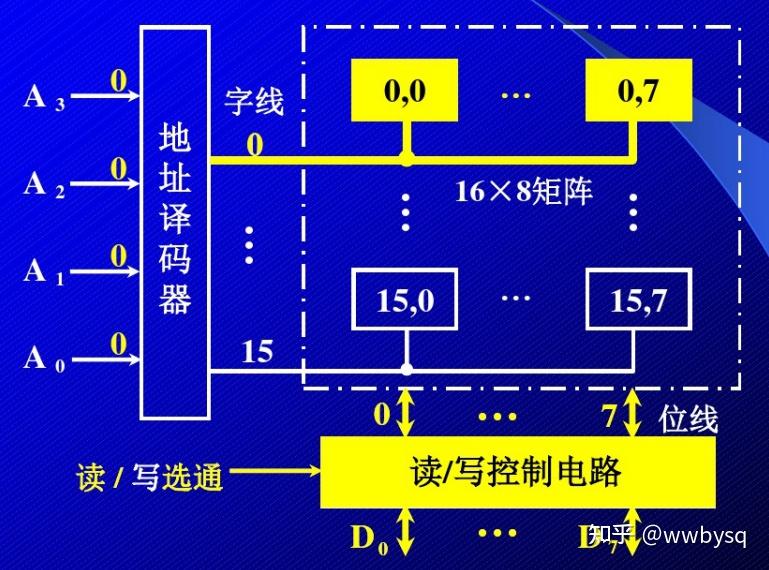
效率
这个字节选择,肯定不是简单你说我们大家都来用字节,我就用字节的,肯定是因为开发效率高,目前c语言最小的数据类型就是char,我们也确实感觉char作为最小用来开发非常简单,如果是一个一个01组合,那不得了,人得疯掉。还有就是执行效率问题,比如我们使用结构体对齐的时候,就知道,这是为了牺牲空间换取时间效率,因为cpu需要提前根据数据类型来进行对应的寄存器调度和处理。如果按照位来操作,那cpu对其和操作就变成非常复杂。其实,还可以举例子呗,就拿flash和eeprom,那我们知道flash都是按照页来进行操作,因为它快啊,不论是刷新还是写入都是快的,因为他是一块一块处理,如果都和eeprom对一个一个位进行操作,不但效率低下,而且内部线路设计也非常复杂。
结语
综上所述,我个人觉得,选择字节作为寻址和编程基础,是经过大家对设计探索和研究所得到最优解。用过keil都知道,都是会选择开启优化2为主的,这也就是处于一个空间和时间相对平衡的过程,不优化和优化3都是一个比较一般的表现。这也是上古时代,前人用时间和实践一步一步走出来的选择,然后再定下来的结构,确实还是很合理的、很可靠的、很好用的。