MCU的图像2d硬件加速
烧录算法
git查询文件
很久没写了
今天也是找bug才有一个方案,就是如何管理git仓库呢.这个问题看起来非常傻逼,但是好像真正实操起来就非常搞人
git log
大家肯定也知道这个操作,就是查询所有提交,我本来是非常讨厌gui的,但是有个ui界面做文件比较是非常人性化的,我也是觉得这个功能非常好啊,一般的gui都是自动log的,所以非常方便,比如vscode的插件,fork,GitHub Desktop等软件,甚至是gitgui都有这个功能,确实是非常不错的,我们只要点击不同版本就能直接查看差异了,而且不是切换过去,所以,这个功能确实非常厉害,但是有个但是,你会发现一个小问题
特定文件
有很多文件,它是多次提交和迭代的,所以,有些bug其实是莫名其妙遗留下来的,万一迭代了上百个版本,然后让你一个一个回去对比,找到log中那么中提交里面有特定文件的演化过程,这就是大海捞针了.
所以,此时就要git log – filename,在log前面加上文件,注意路径,我们就可以通过log来查询特定提交,快速锁定,我目前在网上好像没有找到这种查询特定文件演化过程的功能,不过一个脚本应该可以实现的,目前先一个坑吧,现在确实是可以使用,但是不方便啊,我其实也好奇,git那么多年了,不可能没有人有这种需求啊,都是自己忍受的吗?我相信程序员都是懒鬼的,我看看有空能不能让ai写一个脚本吧,不然真的有点阴间
脚本
有空填坑
脚本代码和实现代码的区别
脚本
常见就是lua,python,shell脚本了,这些脚本可以实现很多系统级别的操作,非常神奇,甚至可以开发上位机,开发游戏等。问题来了,脚本究竟是什么?我们写的代码究竟是什么?其实就是调用系统资源+逻辑+内存。
c语言
相信大部分人,都是c语言开始的,helloworld。但是,为什么会显示出来呢?为什么printf可以打印出来呢?这个大家想过吗?当时肯定是没想过,反正它能打印出字出来,非常好用。
使用这个函数就得有一个头文件,stdio,这个,为什么这个库函数可以使用printf,因为这个函数会调用系统的打印io,从而使得数据得以打印出来,说白了,真正的C语言,如果只是纯粹的语法的话,是不会调用任何系统资源的,完完全全的逻辑和内存代码。
note:我们就会发现为什么c语言移植性那么差啊?因为不同平台的库函数是不一样的,mac,win,linux都是不一样的库函数,所以,同样的c代码,很可能无法公用,必须修改。所以嵌入式设备,无法二次编译,因为,这些消耗本来就少的嵌入式资源。
对比
其实会发现,不论脚本还是c语言其实都是调用系统资源,但是本质是不一样的,因为脚本是调用c语言写好的驱动,而c语言是调用系统的驱动。
想要更加直接的理解区别,我们可以直接尝试使用MCU去动态解析lua代码,对没错mcu动态解析,虽然lua可以编译成luac,但是动态解析就会发现一个事情,其实这个的本质就是c语言的函数指针加上索引实现的,也就是lua解释器生成之后,动态解析时会去检索对应函数指针进行操作处理。也就是说,如果lua语言不对外输入输出,它本质就是一个无意义的行为,一个孤立的代码,不用考虑任何平台和资源的代码,但是一旦要对外输入输出就必须有对外的接口,这个接口就是最好用的键值对了,找到名字调用对应函数即可。
可以参考如下博客:
总结
大家觉得我可能再说废话,其实,不是的,我们要明白一件事,脚本只是调用现有已经实现了的驱动、可执行文件、指令等操作,c语言是可以做到驱动,可执行文件,指令的编写。我们都说c语言是静态语言,其实不完全是的,c语言只是在编译的时候选择了静态编译,不代表它的语言不是动态的,函数指针、内存访问、内核指令操作等,这些就是c语言最大的王牌,这些可以直接控制cpu完完全全可以做到动态去解析其他语言,所以才说脚本语言是动态语言,因为有c语言牺牲了自己来给脚本提供了动态平台,所以,脚本这个层面,一般是不参与底层驱动,而是调用驱动+逻辑处理+文件操作+内存操作等,这些操作都是基于现有存在了才能执行,它们的动态解析器会在动态解析运行时候去检索是否存在调用的行为。
手机开启adb
adb
这个就是cli操作了,就是命令行操作,本质上还是终端那一套来的,ADB 全称为 Android Debug Bridge,起到调试桥的作用,是一个客户端-服务器端程序。其中客户端是用来操作的电脑,服务端是 Android 设备。ADB 也是 Android SDK 中的一个工具,可以直接操作管理 Android 模拟器或者真实的 Android 设备。
adb的下载
不要认为只有linux系统才能搞abd,abd也可以在win上面运行的。
Windows版本:https://dl.google.com/android/repository/platform-tools-latest-windows.zip
Mac版本:https://dl.google.com/android/repository/platform-tools-latest-darwin.zip
Linux版本:https://dl.google.com/android/repository/platform-tools-latest-linux.zip、
根据平台进行选择咯,下载反正都是终端命令行操作的。
adb的环境变量配置
把可执行文件的路径添加到环境变量中,也就是安装包里面的bin文件夹
adb的常用指令和功能
abd就是一个大大的调试工具集合,查看文件、查看ip、查看配置、root、刷机、调用手机功能等操作,来测试或者调试此时设备和系统的可靠性、稳定性、参数等。
手机怎么进入adb模式
进入开发者模式,开启开发者调试功能,开usb的adb调试,确认密钥,就可以进行adb调试。如下的博客,我的也刚好是vivo手机,其他也是差不多的。
adb详细教程(二)-开启手机开发者模式、通过adb连接安卓设备_手机如何进入adb模式-CSDN博客
手机退出安全模式
直接关闭开发者调试模式,这个时候应该还会显示为开发者模式,这个就是内部缓存还没释放,等一会儿,或者重启了,这个时候应该不能使用开发者模式功能,其实也无所谓的。
手机usb实现虚拟网卡测试
此时,我们可以打开,打开两个终端,一个是电脑的,一个专门用来adb的。操作就和git一样,前面要加git。所以,我们就要使用adb shell ifconfig,就可以查到此时手机的所有ip了。
之前也是好奇,手机是怎么通过usb给电脑提供网络的,此时就可以通过adb终端和电脑自身的ipconfig终端来比较,就会发现,此时是手机开启了一个虚拟网卡给电脑使用,这个是通过芯片的BP模块功能实现。这个有点net网络的功能,此时,就是把手机当成一个路由器一样的功能。
我也是很好奇,这个usb设备此时算什么设备呢?usb本身是一个otg通信总线,此时插入之后就被当成网络设备使用了,此时开启了一个虚拟网卡设备,这个就有点意思了蛤,手机新生成的虚拟网卡和电脑的虚拟网卡网段是一样的,此时电脑和手机的实际ip是不一样的,也可以ping通的。哪天再去仔细研究一下,今天就水了。
Qt上位机和嵌入式交互UI的区别
Qt
这个搞嵌入式的,应该到一定程度,就会接触到了,其实就是一个UI+交互的开发软件。我们可以使用Qt来开发安卓,linux,mac等多个平台的软件,尤其是使用PyQt,这个跨平台能力更加夸张,可以一套代码,随意打包成不同平台的可执行软件。
嵌入式平台
我们可以选择在linux或者win等系统上面进行Qt软件的开发,然后通过提供的qmake+交叉编译链,实现对设备的,触摸屏+显示屏的控制,此时就可以实现交互,这种软件,一般都是固定大小的,也不需要缩放,进行点击和操作就行了,帧率也不高。说到底,大小不变,也不用兼容多个设备,只要自己这个屏幕可以健康使用就好了。本质上就是一个linux软件开发,只要设备驱动存在,就没啥问题的。
而且,现在qt都是mcu版本的了,其实也是一样的,就是留个接口,开发人员自己写一个屏幕驱动加进去而已。
上位机
上位机,就可能要玩的花一点了,难一点了咯,要考虑的也更多,不过上位机更多是串口、usb、网络调试等通信接口。
比如隐藏标题栏自定义一个标题栏,注意了隐藏标题栏会导致原本的鼠标缩放功能缺少,需要重新编写鼠标事件才能实现鼠标的拖动缩放。
而且要注意一点就是,控件都是像素大小,而不是屏幕实际大小,但是字体是实际大小,所以,在这个电脑上是正常显示的,但是换一个电脑,换一个屏幕缩放比,甚至只是一个副屏都可能直接出现异常,比如字体现实不全,字体覆盖,字体重叠等诸多问题。开发的时候,要注意时不时的获取一下当前屏幕的像素,重新刷新控件位置和触点、图画等。
有的时候,可能需要手动等比例缩放,可以选择布局,也可以自己根据情况和需求进行修改,果然还是固定大小好啊,不过就算固定代下,也会收到我的分辨率和缩放影响,比我的华为电脑3k 14寸 200%的缩放是异常的,但是公司1080p 24寸 100%缩放是正常的,主要还是因为字体问题,字体大小是实际物理的、是自动跟随系统的,而不是像素大小。
其次就是打包实现跨平台问题,这个是PyQt才能实现的,如果使用C++的打包是非常麻烦的,但是python的打包就非常轻松,不过python开发qt是我非常不看好的,还是c++万岁,虽然确实快。
总结
其实,都是使用控件,然后进行编译,来生成对应平台可执行文件,也都是调用现有的设备,不参与驱动设计,而是纯应用层开发。不过嵌入式软件,一般都是简单,而且屏幕的大小和触摸交互点的位置、大小等固定的,而我们开发的上位机是要兼容多平台,多屏幕,多设备的,交互其实是不难的,而是多多利用状态返回来判断设备和释放设备。
硬件错误带来的问题处理方案
硬件错误
很多时候,就是硬件接口松了,现在的硬件都是挺耐用的,除了那些黑心商家的低温焊锡,廉价的元器件等。有的时候,是用户没安卓驱动,有的时候是用户没接上去,或者中途拔线等,都会导致来自硬件的bug。
在我们软件开发过程中,要分清楚有无系统。是嵌入式开发,还是app开发,还是小程序开发,其实小程序开发就是app的进一步封装来着,只要手机是可以正常使用设备的,小程序也是ok的。这种硬件错误一般都是因为热插拔的问题,也就是pcie和usb等接口设备。
MCU的硬件错误
比如,写了一个USART重定向printf,做一个日志功能。其实就会发现一件事,我们写代码是非常自由的,非常非常爽的。因为我们不论有没有接上去外设总线,我们都能发送,至于读取这个事情,一般都是中断触发。所以,在程序运行过程中,不论总线有没有被插拔,其实都是不影响,mcu的收发的,你说对,mcu只要收发就完事了,而协议考虑的就多了。所以,此时就要有协议回传,就要校验来保证通信是没问题的,不是说,你发送完毕,接收完毕就是OK的,中间线松了也是可以正常通信的。
有系统的MCU
比如rt-thread的smart版本就有一个设备注册和设备查询的操作,这里就封装了文件操作集,open write read那些东西,此时,读写是由返回值的,开发过程中,要注意返回值是真的有用的,是必须要的。对于这些返回状态,可以是一段时间没由回复就为异常,也可以是没有ack,没有片选等诸多方法来判断是否硬件异常。
linux系统
千万不要神话系统了,系统就是为了管理资源和分配任务。有很多总线驱动,这个其实就是上面rt-thread干的事情咯,然后通过vfs来统一接口,所以,应用层开发,就是每次调用文件io的时候,都必须判断返回值是否正常,异常的话,就打印出来,错误是会直接输出出来的,注意咯,标准错误是没有缓冲区的。
1 | FILE *fp; |
这样就可以一定程度上解决来自硬件的错误,所以,我们编写驱动的时候,真的要返回有用的返回值和错误提示,不然应用层真的要爆炸。常见还有就是open成功了,但是读写那些出问题了,比如拔线,此时就得判断,然后fclose文件。
系统开发解决方案
我们都上系统了,那么就肯定要上多线程和多进程的,可以在主线程进行人机交互,子线程进行通信和从机操作等,子线程发现硬件错误,就结束线程,返回给主线程或者修改标准位。此时,就可以在主线程中进行对应操作和反馈用户了,可以等待open成功,也可以结束进程。
代码检错机制
我一开始以为python的异常抛出也就是try,是一个不能乱用的东西,是一个类似于debug固件的东西,不能在release版本存在的东西,后面我才知道,因为python是一个高度抽象的东西,它做不到正常通过代码来识别硬件错误。所以,使用try这种错误机制是可以的哦,不要把它当成一个坏东西,就好比python的一个串口,突然拔了,直接就是write错误,而且非常难处理,此时try抛出是一个非常简单好用的方法哦,尤其是开发上位机的时候。
try可以使用,但是建议少用,这个终究是在逃避,而不是真正的解决问题,而且会增加代码量,如果可以还是避免比较好。嵌入式项目中,用这个try简直就是要命了。因为try会带来新的库,生成文件之后体积明显变大了,尤其是开启了异常处理和堆栈追踪的情况下。
注意了,c中的断言是宏,作用预处理阶段哦,所以,后续程序运行过程是没用的,虽然它可以检测和判断,还能查找文件是否存在。
win使用makefile
没事找事?
为什么要这个呢?因为不论是win还是linux其实都只是一个平台罢了,这个平台想干嘛就干嘛,vscode的终端可以使用dir和ls就说明了,很多软件是可以同时兼容两个操作系统的。
而且很多大牛,逆向实现了win中dll,比如wine,这个团队就实现win中dll库。比如steam掌机是linux系统,也可以运行pc游戏了,非常神奇和高难度的工作哦。
所以说,其实就是一个开发环境罢了
需要安装的东西?
肯定别想win里面有gcc啦!我们去网上下载的ubuntu都没有gcc,要自己安装,同理,也有win32的gcc。
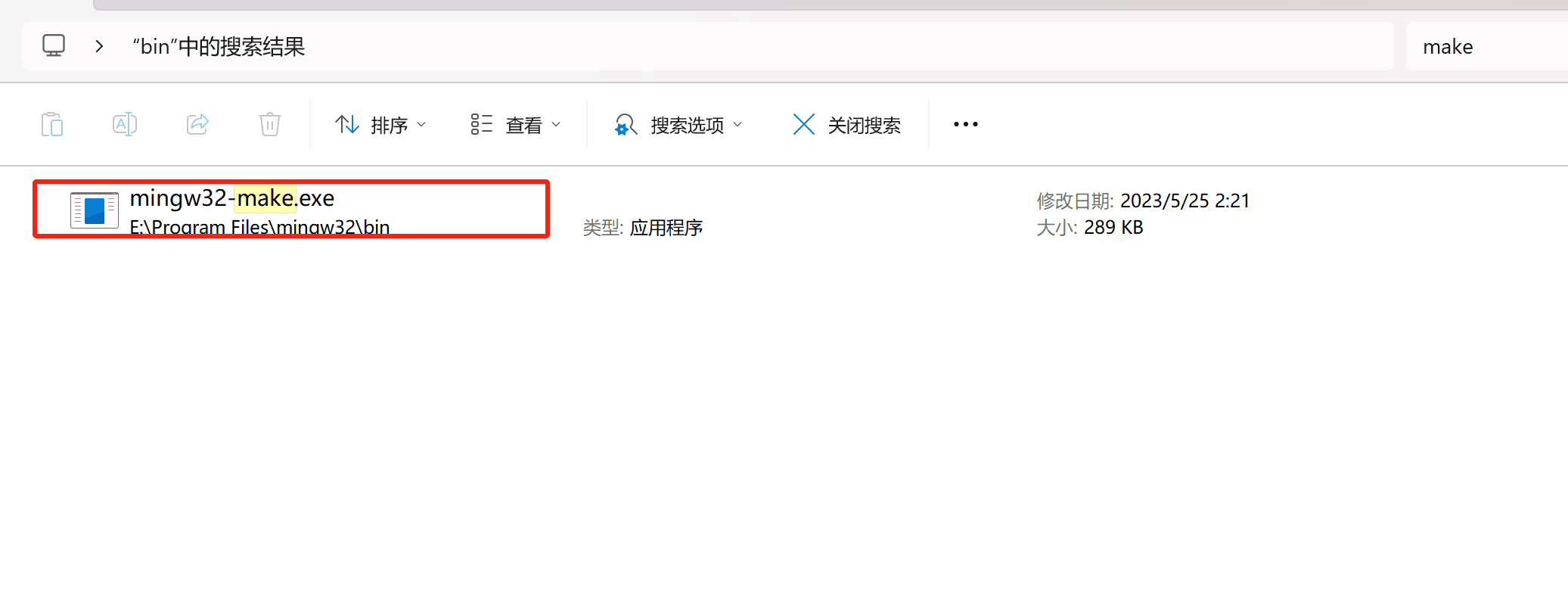
自然makefile也是win没有,有些项目是通过makefile来实现编译的,所以,这就很有必要咯。巧了下面这个MinGW同时有gcc g++等,而且还有makefile哦。但是名字是mingw32-make.exe,最好是复制一份改名字为makefile就好啦。
MinGW下载并安装到自定义的存储中间咯,比如我的:
环境变量
这里,我就多提一嘴吧,毕竟环境变量这种东西,很多小白和工程师都懵懵懂懂的。
其实环境变量顾名思义就是这个开发环境过程中的全局都能使用的变量,这些变量一般都是字符串,或者说是路径,我们脚本类的开发过程中,只有容器这个概念。
1 | csm = "../../csm/csm1/csm2/bin" |
我可以在Path添加一个路径,此时就是一个字符串,不过脚本可以提取并使用出来,这样在文件系统的加持下,我们就能轻易得到这个文件夹中的文件和可执行指令等。
因此我们把git.exe 、gcc.exe、g++.exe等可执行文件添加到对应路径环境变量中,我们在cmd终端就能直接使用git、gcc等来操作,这个有点调用动态库的味道了。
环境变量在linux、win、mac等操作系统都有哦。还有就是win的多用户情况下的环境变量了。也就是分成系统变量和用户罢了。
其实也非常好理解,一个win一个linux本身就不是一个用户,本身就支持多用户使用和操作的,所以,为了每个用户量身定做,也是非常合理的,常见的就是安装程序的时候,会弹出来是否为了本机所有用户安装,其实这就是系统环境变量了。
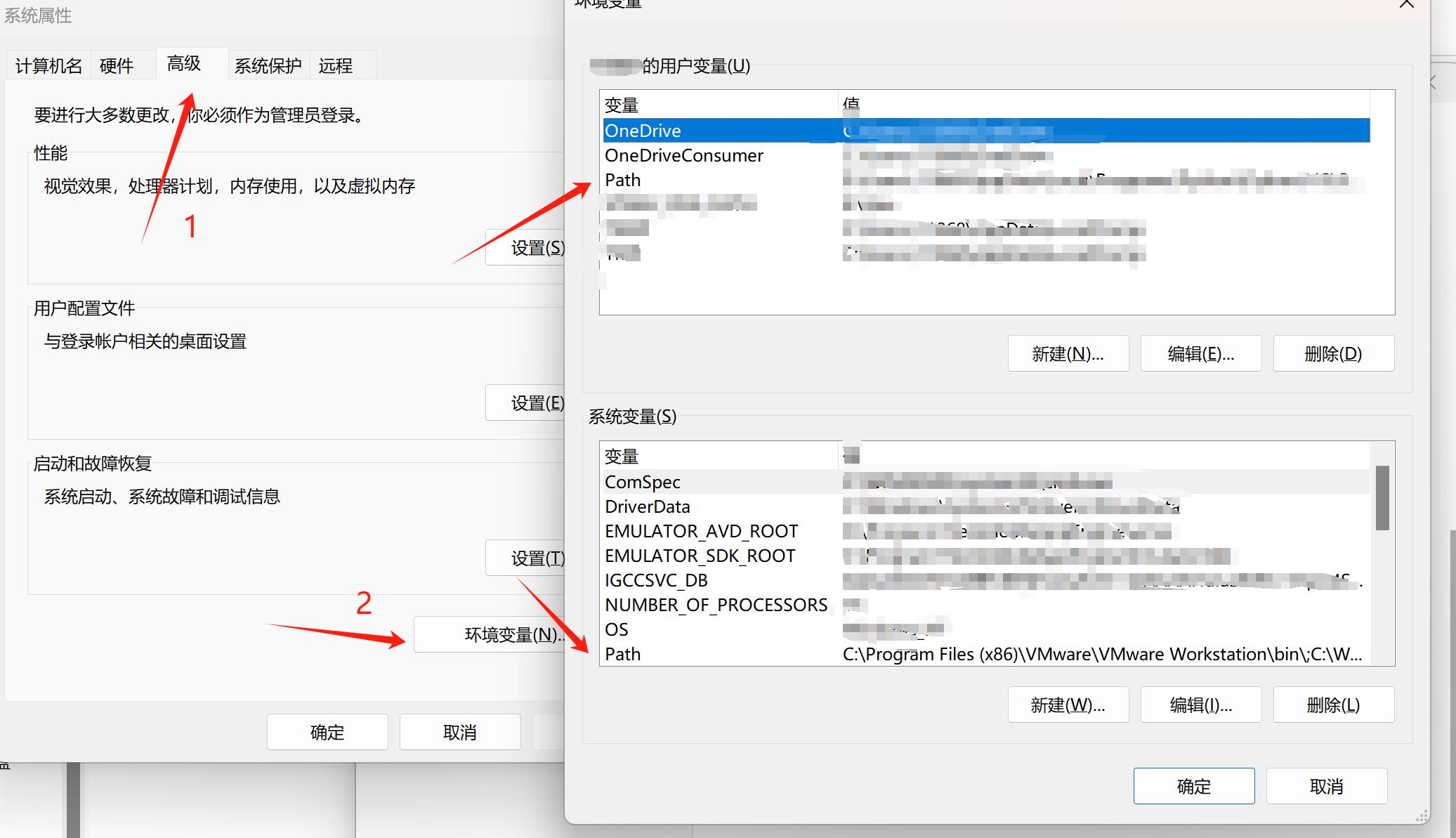
环境变量优先级和顺序
我们在用户变量和系统变量中创建同名变量,那么windows会将用户变量覆盖系统变量。
windows下用户变量和系统变量的优先级_window 让用户环境变量 优先于 系统环境变量-CSDN博客
同一个环境下,从前往后开始查询变量,所以,好巧不巧,我这里有一个minGW32的bin在后面,前面又有一个老版本的minGW32里面自然也有bin,我把它放在新版后面,就会导致系统和开发环境调用老版本的gcc、g++等东西,出现的结果可能就差强人意了。
windows环境变量PATH顺序的重要性 - 阿玛尼迪迪 - 博客园
总结一下咯
其实,不论win,还是mac,还是win等,其实都是一个操作系统环境,内部都有脚本的,都有文件系统和路径,有win的盘系统,有linux、unix的根系统,都是有路径来的,而环境变量就是最好路径描述。
1 | #总不能前面加上一长串的地址然后执行一个git? |
所以,平台只是一个平台,只要满足他的开发环境就可以使用,巧了不是gcc、python那些编译链刚好有很多平台版本的,环境ok就可以用了。
嵌入式web
Web是什么呢?
Web(World Wide Web)即全球广域网,也称为万维网,它是一种基于超文本和HTTP的、全球性的、动态交互的、跨平台的分布式图形信息系统。是建立在Internet上的一种网络服务,为浏览者在Internet上查找和浏览信息提供了图形化的、易于访问的直观界面,其中的文档及超级链接将Internet上的信息节点组织成一个互为关联的网状结构。
自然咱们搞开发,肯定是能看懂一二?看懂给鬼啊?搞嵌入式哪里会这些东西。这些一看就是前端后端那些要完蛋的东西。但是,其实还是有些地方的前端工资有很高,就算在卷,一个项目最终要一个人,一个团队审核,所以说,肯定是要有人会的,这种级别的大佬,工资不低哦,不是说搞前端工资高,而是全栈,啥都会,cto,技术总监那种同时会前端,自然是香的。
说白话,就是用户看不懂开发,连抓包都不会的,看状态,查bug就更不可能了,只有简洁好用的界面还差不多。那么有啥东西,通用又简单,而且不用下载软件,不吃设备呢?欸!我有一个点子,铁牛牛肉面(bushi)。开玩笑,那就是浏览器了。
浏览器和内核
首先,内核是浏览器的核心,这个操作系统是一样的,外部就是浏览器了,也就是这个内核的套壳。
浏览器,这东西见怪不怪了。浏览器开发含金量有,但是不是很高,你觉得百度怎么样?我觉得是依托,但是它的开发难度确实不低。
浏览器内核,这东西的含金量才高的吓人,真的非常非常非常非常牛逼,他的代码量非常大,而且现在国外基本都是Google的引擎,市场率好像是68%,至于bing的内核也是好东西,那是因为微软强行带它玩的,真正厉害的引擎还是google内核,不过这个优劣就不讨论了,总比国内的套壳百度好太多了。
开发一个浏览器的内核难度,绝对不亚于开发一个操作系统,里面有多到骇人的协议栈,有非常多的标志位,是依托大大的屎山,但是没人敢乱动它。它可以做到所有平台下的兼容,这点真的真的太牛逼,确实是系统根据浏览器内核留下来的接口,进行对接才实现的。因此用户不用担心平台设备问题,可以随心所欲使用浏览器,虽然主要功能是显示和交互,但是难度真的不低,要兼容历史遗留,浏览器内核要兼容各个浏览器。自然咱们搞屌嵌入式的,这个自然是用用就好了,顶多抓个包,逆向一些东西捞点钱罢了。
为什么一直以来都没有国产浏览器内核,研发一个究竟有多难?_标准
(5 封私信) 自主研发一款浏览器内核的难度到底有多大? - 知乎
嵌入式Web用途呢?
这个啥意思呢?我们大部分使用Web都是在电脑上,也就是PC(Personal Computer)上面,使用浏览器查看的,但是嵌入式设备不是电脑,嵌入式就是一个垃圾电子,它贯彻够用就行,所以,很多时候都不能二次开发,系统裁剪,内存裁剪,存储裁剪,所以,它是一个方向的极致设备了,不同电脑是可以执行多种操作,想干嘛就干嘛,只要有资源和条件。
note: 我只是要控制USB的一个灯泡,总不能买一个mac电脑,对usb进行一个代码编写,然后就为了控制这个灯泡吧。那其他硬件不都浪费,所以,嵌入式就是这种”剪身成蝶”的设备了,剪出来一个合适的大小,满足需求即可咯。
用途:Web肯定是联网的,但是可以是广域网,也可以是局域网咯。
最最最常用就是配置无线路由器了,这个是通过手机浏览器或者电脑浏览器去访问特定浏览器地址,然后就能进入一个Web界面,这个界面其实就是为了帮助用户来进行修改属性的,用户肯定是不可能看得懂这些代码和开发的,但是开关和设备那些,输入账号密码,还是有可能会的。也就是说,Web就是为了防呆,就是为了让用户可以低成本实现对硬件配置,用户通过交互让本地的路由器得到数据,然后路由器把本地的页面传给用户端,也就是类似软件一样的交互和操作了,不过这一切都是发生在Web上的。但是还有用很多用户不知道怎么操作和设置属性,建议多去网上搜一下视频和教程吧,低成本快速入手,不意味着啥也不用操作,等着饭送到嘴边,不想动脑就得花钱请人,就是那么简单。咱们嵌入式工程师都来写前端了,你还想让我们怎么样啊,呜呜呜。
我们知道了,其实就是通过了网络来进行通信,自然就可以远程控制和修改属性,比如我家里面有一个智能管家,我要远程去修改他的参数,我是用户啊,我肯定看不懂,只有相对合理的配置界面还差不多,让用户输入命令行,等着退货和差评吧。此时需要哪个智能管家连上网络,对接到厂商提供的服务器。我们打开app,然后app就会去访问服务器,我们发送查询请求,服务器就会去查询我们绑定的嵌入式设备,然后把它的Web数据发送给服务器,服务器再转发给我们app上面,此时我们就知道嵌入式设备的属性和状态啦,我们修改一下,再确定上传就完成对设备的操作咯。这里服务器可以选择解析Web数据,然后再发送给我们app,也可以作为一个透传功能。
有人要问了,为什么不用mqtt协议啊?我只能说,孩子,你高估用户的编程开发水平了,他们要是看得懂数据和拆包,我们可以下岗了。http、https和mqtt都是基于tcp\ip的封装,mqtt确实高效实时,但是用户看不懂,除非你在app层面对这些数据进行处理,也是可以的,Web就是为了交互和不限设备、以及安全性。想那种智能家居,估计用就是mqtt了,但是一开始配置联网的过程很可能用到了Web;
一句话总结:
首先要有网络,现在一般都是无线网络;其次要配置网络连接、网络属性或者参数;有无远程访问寻求;裁剪程度和设备复杂度;有无app开发,需不需要;给谁用,受众是谁。
嵌入式Web的主要组成部分
1.Web服务器:
- 嵌入式Web服务器是运行在嵌入式设备上的Web应用服务器,它负责处理HTTP请求、返回网页内容,并与设备的硬件或操作系统进行交互。
- 常见的嵌入式Web服务器包括:uHTTPd、lighttpd、Nginx、Apache(虽然主要用于PC,也可以在某些嵌入式设备上运行),以及专为嵌入式设计的mongoose、libmicrohttpd等。
2.Web前端:
- 前端界面是通过Web浏览器访问的HTML、CSS和JavaScript组成的网页。用户通过这些网页与嵌入式设备进行交互。
- 在嵌入式设备中,前端界面往往需要精简,以适应低资源的硬件环境。通常会使用轻量级的前端框架,如Bootstrap、jQuery,甚至定制的前端代码来减小资源消耗。
3.Web后端:
- 后端通常由嵌入式设备中的应用程序或控制器提供,处理前端请求、控制设备硬件、管理数据等。
- 后端编程语言有很多选择,可以使用嵌入式开发语言(如C/C++、Python)或嵌入式操作系统提供的API(如RTOS)进行开发。
4.协议和接口:
- 嵌入式Web通常通过HTTP协议进行通信,也可以使用WebSocket进行双向通信,尤其适用于实时数据交互。
- 数据通常采用JSON或XML格式进行传输,以便在Web客户端和嵌入式设备之间交换信息。
LWIP
这个是为了实现最最最基础的网络通信咯,也就是tcp\ip或者utp通信,我们开发者可以通过socket在嵌入式上面运行咯,甚至mcu都能使用这个socket,非常非常牛逼,从网上下载对应的库,然后查看手册进行编程吧,这里是需要一些网络编程基础的,可以先去学一下linux的网编再来从事这个lwip库吧。
也可以查考下面这个博客,搭建一个嵌入式web服务器操作哦。
手把手教你在开发板中搭建一个嵌入式web服务器-CSDN博客
需要掌握的网络协议
ICMP、TCP\IP、UDP、Http、Https、CoAP、Mqtt、WebSocket、REST、SOAP、UPnP、FTP/SFTP、SNMP、BASIC/Modbus TCP(这个了解就好了)等,还有非常非常多协议。建议找一个开源项目尝试一下哦。
总结
就是为了让用户看懂和快速上手操作的交互界面,嵌入式设备内部存放这web页面数据,通过连接之后,用户通过浏览器进入对应ip,就会向嵌入式设备发送web请求得到,然后就会发送web页面到用户浏览器中,就可以进行交互操作了,嵌入式设备就可以因此得到想要的数据了。
note:不是只有linux嵌入式设备才能有所谓的web功能,只是因为大部分物联网嵌入式设备,直接mqtt就ok了,用不着web,也不需要用户来交互,一个app控制网络就好了。如果你想要,用mcu也可以实现web功能,看需求咯。